Cloud Platforms, Data Warehouses, Data Lakes, and Lakehouses — What's the Difference, Really?
What is the difference between Cloud Platforms, Data Warehouse, Data Lake, and Lakehouse?
DATA ANALYTICS BLOG POSTS
Boniface Mibei
4/19/20269 min read
INTRODUCTION
If you've ever sat in a meeting where someone casually threw around "we'll put it in the lake" or "spin up a warehouse" — and nodded along while having absolutely no idea what they meant — this article is for you.
The world of data infrastructure can feel like alphabet soup — AWS, GCP, S3, Redshift, Snowflake, Databricks, Delta Lake. Everyone seems to be talking about it, job descriptions are full of it, and if you're building a career in data, you'll eventually need to not just recognise these terms, but genuinely understand what each one does and why it exists.
Here's the thing though: these four concepts — cloud platforms, data warehouses, data lakes, and data lakehouses — are not competing technologies. They are different layers of a data infrastructure stack, each solving a different problem that emerged at a different point in time. Understanding the distinction between them is one of those foundational things that makes everything else in the modern data world click into place.
Let's break it down, from the ground up.
────────────────────────────
SECTION 1: CLOUD PLATFORMS — THE FOUNDATION EVERYTHING ELSE SITS ON
DEFINITION:
A cloud platform is a suite of on-demand computing services — including servers, storage, networking, databases, AI tools, and more — delivered over the internet by a provider who manages the physical infrastructure.
Think of a cloud platform as a city. It has roads, buildings, electricity, water, telecommunications, and every kind of facility you might need. You don't build the city — you just rent space in it and use whatever services you need.
Before cloud platforms existed, companies had to buy their own physical servers, house them in their own data centres, hire teams to maintain them, and hope they had enough capacity when traffic spiked. It was expensive, inflexible, and slow. Cloud platforms changed all of that. Now you can spin up a server in minutes, scale storage automatically, and only pay for what you use.
THE BIG THREE CLOUD PLATFORMS
1. Amazon Web Services (AWS)
AWS is the oldest and still the largest, launched in 2006. It offers over 200 services — from virtual machines (EC2) to object storage (S3) to machine learning tools (SageMaker). If you've ever used Netflix, Airbnb, or LinkedIn, you've indirectly used AWS.
2. Microsoft Azure
Azure is the natural home for organisations already deep in the Microsoft ecosystem — think enterprises running Windows Server, Active Directory, and Office 365. Azure integrates tightly with all of these, making it the dominant choice in corporate and government environments.
3. Google Cloud Platform (GCP)
GCP is the youngest of the three but arguably the most developer-friendly. Google built it to run the same infrastructure that powers Search, YouTube, and Gmail — so it's exceptionally good at handling massive-scale data processing.
ANALOGY:
A cloud platform is like renting space in a fully serviced business park. You get electricity, internet, security, and offices — and you only pay for what you use. You don't buy the land, build the building, or hire the security guards. That's all taken care of.
It's important to understand that cloud platforms are not specifically data tools. They are general-purpose infrastructure. Data warehouses, data lakes, and lakehouses are built on top of cloud platforms — they are specific products that run within this broader ecosystem.
────────────────────────────
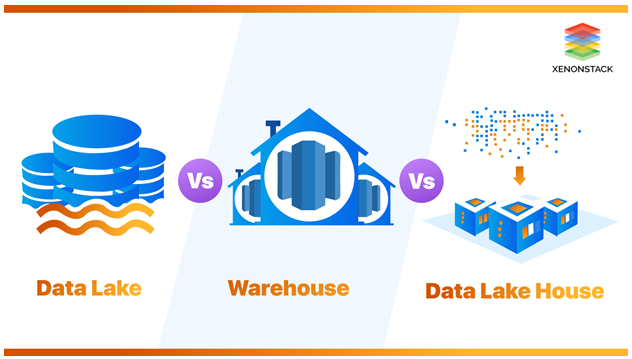
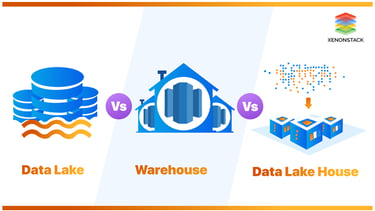
SECTION 2: DATA WAREHOUSES — THE TIDY, ORGANISED FILING CABINET
DEFINITION:
A data warehouse is a centralised storage system designed specifically for structured, processed data that is optimised for fast analytical querying. Data enters the warehouse already cleaned and organised, ready to be analysed.
Data warehouses have been around since the 1980s, but they came into their own in the cloud era. The idea is simple: you take data from various operational systems — your CRM, your ERP, your sales platform — clean it up, transform it into a consistent format, and load it into a single, well-organised repository where analysts can query it at speed.
This process is commonly called ETL — Extract, Transform, Load. You extract data from source systems, transform it (cleaning, reshaping, standardising), and load it into the warehouse.
WHAT MAKES A DATA WAREHOUSE SPECIAL?
Data warehouses are purpose-built for analytics, not for day-to-day transactions. They use a columnar storage format, which means instead of storing data row by row (like a spreadsheet), they store it column by column. This makes aggregation queries — "what were total sales by region last quarter?" — dramatically faster.
They also enforce a strict schema-on-write principle, meaning the structure of your data must be defined before you load it. This keeps data clean and consistent, but it also means they are less flexible with unstructured or raw data.
LEADING DATA WAREHOUSE EXAMPLES:
- Snowflake
- Google BigQuery
- Amazon Redshift
- Azure Synapse Analytics
Snowflake is perhaps the most celebrated modern data warehouse. It separates compute from storage, meaning you can scale each independently. It's cloud-agnostic, running on AWS, Azure, and GCP, and its clean interface makes it approachable for analysts while remaining enterprise-grade for engineers.
Google BigQuery is serverless — there are no clusters to manage, no infrastructure to configure. You load your data, write a SQL query, and BigQuery figures out the rest. It's famous for being able to query terabytes of data in seconds.
Amazon Redshift is the warehouse for teams already embedded in the AWS ecosystem. It integrates deeply with other AWS services and is extremely powerful for large-scale analytics.
REAL-WORLD EXAMPLE:
Imagine a retail bank. Every day, thousands of transactions flow through its systems. At the end of each day, those transactions are cleaned, standardised, and loaded into a data warehouse. A business analyst can then run a query asking "how many customers made more than 10 transactions in the past 30 days?" and get the answer in seconds — because the data is already structured, clean, and indexed for exactly that kind of question.
────────────────────────────
SECTION 3: DATA LAKES — THE GIANT STORAGE ROOM
DEFINITION:
A data lake is a centralised repository that stores data in its raw, native format — structured, semi-structured, and unstructured — at any scale, until it is needed for analysis.
Data warehouses are powerful, but they have a significant limitation: they only handle structured data well. What about log files? Customer survey responses? Images? Social media streams? IoT sensor readings? These types of data don't fit neatly into rows and columns, and they can't easily be transformed upfront because you often don't know how you'll want to use them yet.
The data lake emerged to solve this problem. The concept, popularised around 2010, was simple: store everything, transform later. Dump all your data — raw, messy, unstructured, whatever it is — into a single cheap storage location. When you need it, you figure out what to do with it.
SCHEMA-ON-READ VS SCHEMA-ON-WRITE
This is the key philosophical difference between a data lake and a data warehouse:
- A warehouse uses schema-on-write — structure is enforced when data goes in.
- A lake uses schema-on-read — you define the structure only when you read the data, depending on what you need it for.
This makes data lakes extremely flexible and cheap to maintain. Raw storage on cloud object storage like Amazon S3 is orders of magnitude cheaper than warehouse storage. But without discipline, a data lake quickly becomes a "data swamp" — a chaotic pile of raw files where nobody knows what's in there, data quality is unknown, and querying is painfully slow.
LEADING DATA LAKE TECHNOLOGIES:
- Amazon S3
- Azure Data Lake Storage (ADLS)
- Google Cloud Storage
- Hadoop HDFS
REAL-WORLD EXAMPLE:
A music streaming platform collects enormous volumes of raw data every second — song plays, skip events, search queries, playlist activity, device type, location. None of this fits into a neat table. They dump all of it into a data lake (say, Amazon S3). Later, a data scientist wanting to build a recommendation model can access the raw events and structure them however the model requires. A separate analyst wanting to count monthly active users pulls out only what they need. The same raw data serves many different purposes.
WARNING — THE DATA SWAMP PROBLEM:
Without governance, data cataloguing, and quality controls, data lakes become unmanageable. Data teams have spent years battling the "swamp" problem — data that exists but nobody trusts, can find, or knows how to use. This limitation directly inspired the lakehouse.
────────────────────────────
SECTION 4: DATA LAKEHOUSES — REFUSING TO CHOOSE
DEFINITION:
A data lakehouse combines the low-cost, flexible storage of a data lake with the data management, governance, and query performance features of a data warehouse — in a single, unified architecture.
By the mid-2010s, most data teams were running two parallel systems: a data lake for raw storage and machine learning, and a data warehouse for structured analytics and reporting. Moving data between the two was painful, created duplication, and introduced consistency issues. Keeping both systems in sync was a full-time job.
The lakehouse architecture — a term popularised by Databricks — emerged as the answer. The core insight was: what if you could add warehouse-like structure and governance on top of lake storage, rather than moving data to a separate warehouse?
WHAT MAKES A LAKEHOUSE DIFFERENT?
Lakehouses use open table formats — most notably Delta Lake, Apache Iceberg, and Apache Hudi — that sit on top of raw storage and add features like:
- ACID transactions (reliable, consistent writes)
- Schema enforcement
- Time travel (querying historical versions of data)
- Data versioning
In plain English: you keep all your data in cheap object storage, but you layer a smart management system on top that makes it behave like a well-organised warehouse — without the cost of moving data or maintaining two separate systems.
LEADING LAKEHOUSE PLATFORMS:
- Databricks (built around Apache Spark and Delta Lake)
- Apache Iceberg
- Delta Lake
- Google BigLake
- Microsoft Fabric
THE BUILDING ANALOGY:
A data warehouse is a tidy, well-organised office library. Every book is catalogued, shelved correctly, and easy to find — but you can only keep books, not random objects.
A data lake is a massive warehouse where you store everything — books, tools, boxes, loose papers, equipment — but finding anything specific is a challenge unless you have a great inventory system.
A data lakehouse is the same massive warehouse, but now someone has installed smart shelving, a digital catalogue, and automatic organisation systems — so you can store everything AND find it quickly.
────────────────────────────
SECTION 5: HOW WE GOT HERE — A BRIEF HISTORY
1980s – 2000s: THE AGE OF DATA WAREHOUSES
Companies like Teradata and IBM built on-premise data warehouses to centralise structured business data. Expensive, powerful, but rigid and hard to scale.
2006 – 2012: THE RISE OF CLOUD AND BIG DATA
AWS launched S3 (2006) and Redshift (2012). Hadoop emerged as an open-source big data framework. Data lakes became a concept for storing massive volumes of raw data cheaply.
2012 – 2020: CLOUD WAREHOUSES MATURE
Snowflake and BigQuery revolutionised analytics with cloud-native warehouses. Teams ran dual architectures — a lake for raw data and a warehouse for reporting — and struggled with the friction between them.
2020 – PRESENT: THE LAKEHOUSE ERA
Databricks popularised the lakehouse architecture with Delta Lake. Open formats like Apache Iceberg gained momentum. Microsoft Fabric and Google BigLake entered the scene. The industry began converging on unified architectures.
────────────────────────────
SECTION 6: SIDE-BY-SIDE COMPARISON
[You can recreate this as a table in your website builder]
Feature | Cloud Platform | Data Warehouse | Data Lake | Data Lakehouse
--------|---------------|----------------|-----------|------------
Primary Purpose | General infrastructure | Structured analytics | Raw data storage | Unified analytics + ML
Data Types | Anything | Structured only | All types | All types
Schema | N/A | Schema-on-write | Schema-on-read | Both supported
Query Performance | N/A | Excellent | Slow (raw) | Good to Excellent
Cost | Pay as you go | Higher | Very low | Medium
ML / AI Support | Yes (via services) | Limited | Yes | Native
Data Governance | Varies | Strong | Weak | Strong
Examples | AWS, Azure, GCP | Snowflake, BigQuery, Redshift | S3, ADLS, GCS | Databricks, Delta Lake, Iceberg
────────────────────────────
SECTION 7: WHICH ONE SHOULD YOU USE?
Here's the honest answer: in most real-world organisations, you're not choosing one over the others. You're choosing a combination — and the right combination depends entirely on your use case, team size, and data maturity.
IF YOU'RE A SMALL BUSINESS OR STARTUP ANALYST...
You probably don't need a data lake or a lakehouse yet. Start with a cloud data warehouse — BigQuery if you're on GCP (it's free to start and requires zero setup), or Snowflake if you want something more flexible. Connect it to your BI tool of choice (Power BI, Tableau, Looker) and you'll cover 90% of your analytical needs.
IF YOU'RE A GROWING COMPANY WITH DIVERSE DATA SOURCES...
You likely need both a data lake (for raw storage of event data, logs, files) and a warehouse (for clean, structured reporting). AWS S3 + Redshift, or GCP Cloud Storage + BigQuery, are tried and tested combinations. Consider adding a transformation layer like dbt to manage the pipeline between them.
IF YOU'RE A DATA-MATURE ORGANISATION RUNNING ML/AI WORKLOADS...
This is where the lakehouse starts to make sense. Databricks on AWS or Azure gives your data engineers and data scientists a single unified platform — no more moving data between systems. The upfront complexity is higher, but the payoff is significant at scale.
PULL QUOTE:
"Don't pick the most sophisticated architecture — pick the simplest one that solves your actual problem today, with room to grow tomorrow."
A word of caution: it's tempting to build the most sophisticated architecture you've read about, especially when you're early in your data journey. Resist the urge. A well-governed data warehouse will serve most organisations far better than a poorly-managed lakehouse. Complexity should be earned, not assumed.
────────────────────────────
CONCLUSION: FINAL THOUGHTS
Let's bring it all together with a simple mental model:
Cloud Platforms are the city — the infrastructure everything else is built on. AWS, Azure, and GCP are the three dominant ones.
Data Warehouses are the organised library within that city — purpose-built for fast, structured analytics. Snowflake, BigQuery, and Redshift are the leaders.
Data Lakes are the vast storage facility — cheap, flexible, and happy to hold anything raw. Amazon S3, ADLS, and Google Cloud Storage power most of them.
Data Lakehouses are the smart hybrid — giving you the storage flexibility of a lake with the structure and performance of a warehouse. Databricks and Delta Lake are at the forefront.
The modern data stack is not one tool — it's a thoughtfully assembled collection of layers, each doing what it does best. The analysts and engineers who understand these distinctions aren't just better at their jobs — they're better at having the right conversations, making the right technology decisions, and building systems that actually scale.
And that, in 2026, is a genuinely valuable skill.
By:
Boniface Mibei | Boniface@bkdataanalytics.com